Research Labs
How Do You Build a Marketing Tech Stack That Doesn't Break at 100 Locations?
Scaling a marketing tech stack across multiple locations is an operational challenge, not just a software one. Here's what breaks, why it breaks, and how mature organisations build systems that actually hold.
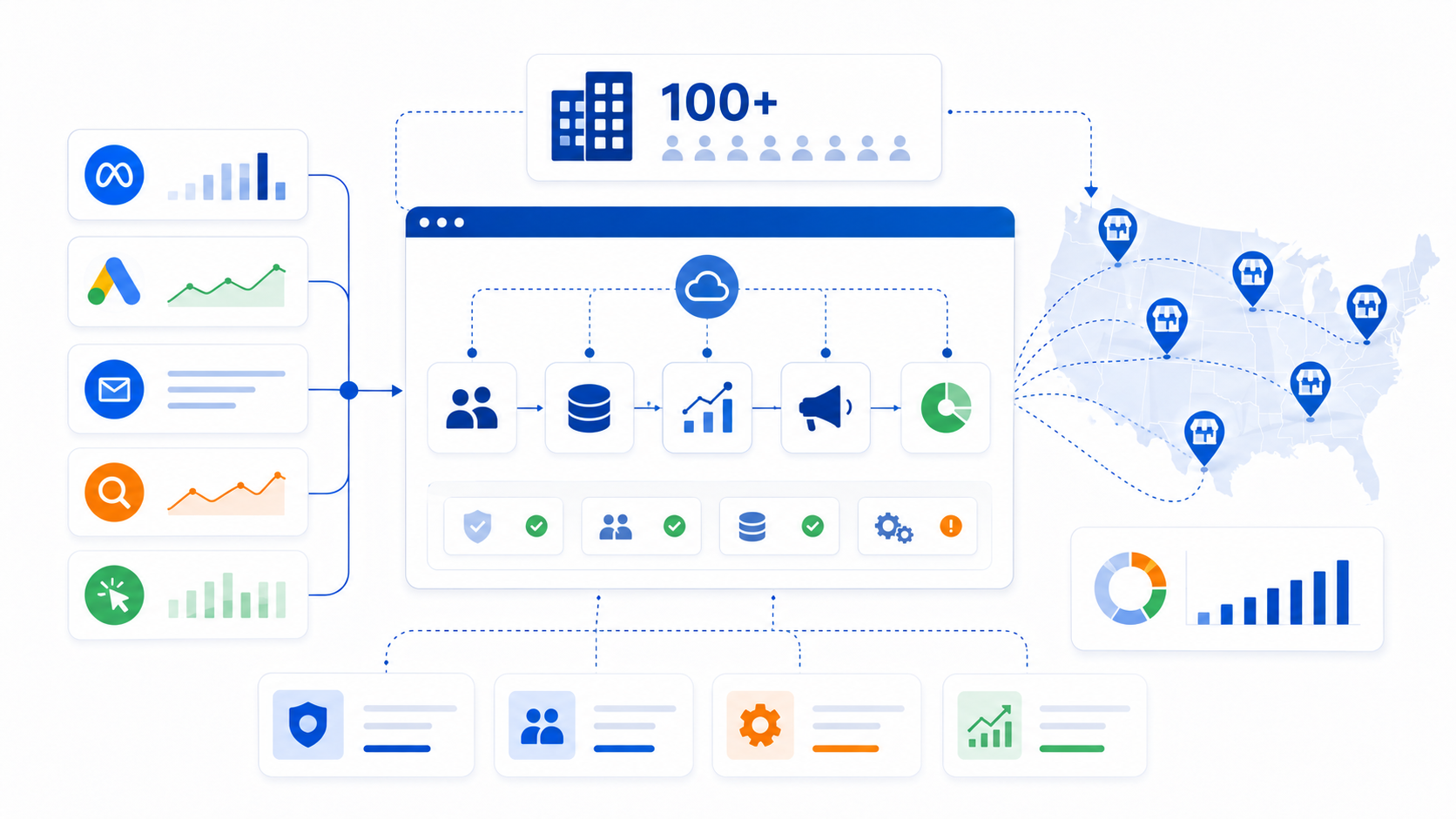
Most marketing tech stacks are built for the pitch deck, not the operations manual. They look impressive in a slide: interconnected platforms, data flowing smoothly between systems, dashboards surfacing insights in real time. What that diagram never shows is the moment when location 47 onboards and someone realises there is no clear owner for setting up their CRM profile, or that the reporting system requires a manual export every Monday because two platforms never actually integrated the way the vendor said they would.
This is the gap that breaks companies as they scale. Not a lack of tools, but a fundamental misunderstanding of what a stack is supposed to do at volume. Adding software is not the same as building a system. A collection of disconnected platforms, each chosen for what it does individually, does not become infrastructure just because they share a vendor invoice. Infrastructure is what holds together when things get complicated. Multi-location marketing gets complicated in ways that most technology evaluations never anticipate.
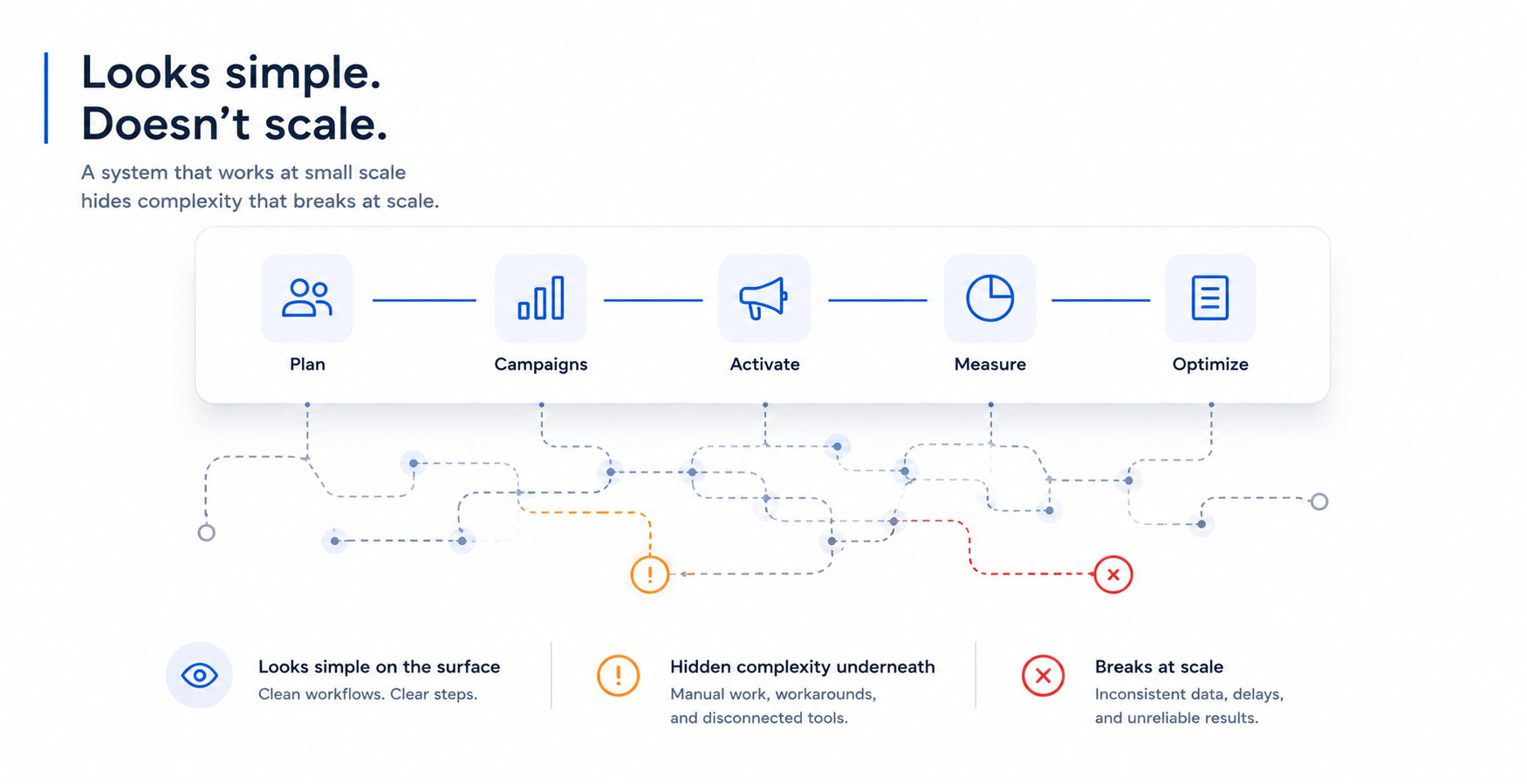
Why What Works at Five Locations Collapses at Fifty
The early stages of multi-location growth are forgiving. With a handful of locations, a central team can compensate for gaps in tooling through direct involvement. Someone at HQ knows which campaigns are running where. Someone manually checks that local social accounts are posting on-brand content. Someone catches the data discrepancy before it becomes a reporting problem because they are close enough to the work to notice.
At fifty locations, that proximity disappears. The systems were never designed to see everything on the central team’s behalf. What emerges is a strange combination of over-reliance on manual processes that were always meant to be temporary, and under-reliance on platforms that were purchased but never fully implemented.
The failure modes are predictable in hindsight. CRMs that made sense for a single market now hold inconsistently structured data because each location set up its own fields and conventions. Campaign workflows designed for a central team running three markets now require someone at HQ to manually replicate assets for thirty. Attribution models that worked when traffic was simple now produce meaningless numbers because the customer journey crosses locations, devices, and channels in ways the original model was never built to track.
The irony is that most of these problems were visible at fifteen or twenty locations. They just felt manageable. The instinct at that stage is to patch rather than rebuild: add an integration here, hire someone to manage the spreadsheet there, create a workaround for the platform that cannot do what you need. By the time the patches become the system, the technical debt is structural.
The Hidden Operational Complexity Nobody Prices In
When companies evaluate marketing software for a multi-location business, they tend to focus on features and price per seat. What they underestimate consistently is the operational cost of implementation at scale: the human time required to onboard each location, the training burden, the ongoing support load, and the governance overhead of maintaining data quality across dozens of operators with varying levels of technical comfort and varying interest in following a process they didn’t design.
A platform that requires thirty minutes of setup per location sounds fine in a spreadsheet. At 100 locations, that is fifty hours of setup before a single campaign runs. And setup is the easy part. Six months later, some locations have updated their information and some haven’t. Some have integrated the platform into their daily workflow and some are still doing things the old way because nobody followed up.
This is where process design starts to matter more than software selection. The best platform underperforms if there is no clear protocol for how locations interact with it, who owns the data inside it, what happens when something goes wrong, and how the central team monitors quality without creating an unbearable reporting burden for local operators. Most technology purchasing decisions happen before any of these questions are answered, which is why so many stacks look functional at point of purchase and chaotic twelve months into deployment.
Standardisation Without Suffocation
Finding the Line Between Consistency and Control
The central tension in multi-location marketing infrastructure is not actually a technology problem. It is a design philosophy problem. How much of the system do you lock down centrally, and how much flexibility do you build in for local variation?
Lock down too much, and local operators lose the ability to respond to their specific market conditions. A franchisee in a densely competitive urban market has different needs than one in a regional town with low competitive intensity. A location serving a customer base that skews younger and digitally native needs different channel emphasis than one serving an older demographic that still responds to direct mail and local radio. A system that forces both locations into identical workflows and identical channel mixes will underserve both.
Leave too much open, and you lose the consistency that makes the brand function as a system rather than a loose collection of independent operators. Inconsistent customer data across locations makes centralised reporting unreliable. Inconsistent campaign structures make it impossible to understand what is actually driving performance. Inconsistent brand execution erodes the recognition that makes national brand investment worth making.
The organisations that handle this well tend to draw the line at outputs rather than inputs. They standardise the data structures, the reporting frameworks, the brand assets, and the core campaign architecture. They leave local operators room to choose how they activate within that framework: which locally-relevant events to promote, which community partnerships to feature, which content angles to emphasise given what they know about their specific audience. The system provides the structure. The local operator provides the judgment about what goes inside it.
This requires more upfront design work than most organisations invest in. It requires thinking through what actually needs to be uniform for the system to work, versus what has been made uniform out of habit or convenience. But the payoff is a stack that local operators actually use because it gives them something useful rather than just adding compliance burden.
The Common Mistakes That Compound Over Time
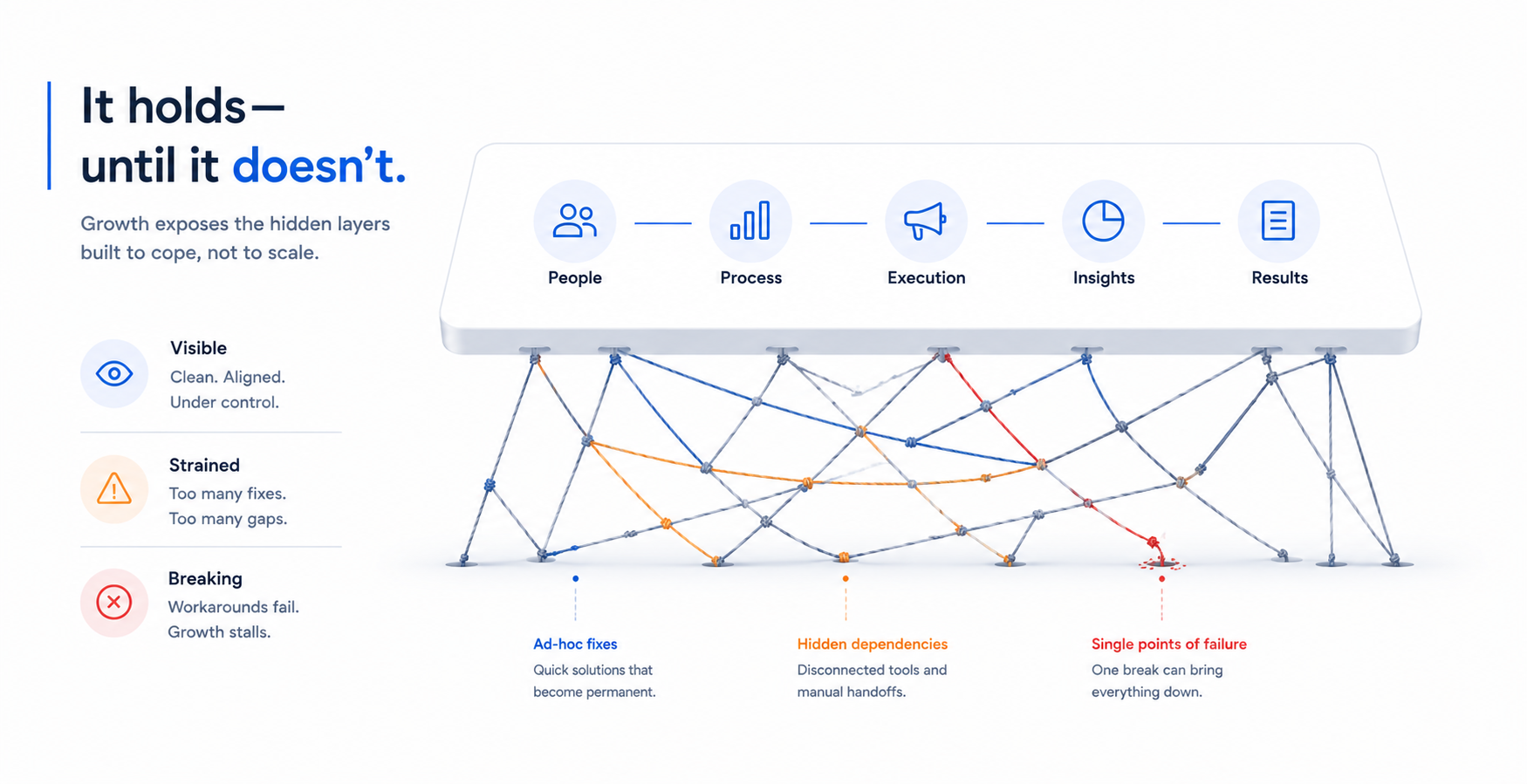
There are a few recurring patterns in how multi-location marketing stacks go wrong that are worth naming directly, because they are not obvious until you have seen them play out.
Buying for aspiration rather than current state. A platform with sophisticated AI-driven personalisation features sounds compelling until the locations feeding it have inconsistent customer data, no clear segmentation logic, and a local team without the bandwidth to use half of what the platform can do. The feature you need at 200 locations should not be driving your purchasing decision at 20. Buy for where you are and what you can actually implement.
Underestimating the integration layer. Every additional platform creates a dependency that requires maintenance, breaks when either system updates, and needs someone who understands both sides to diagnose problems. The more complex the integration layer, the more brittle the entire stack becomes. The instinct to solve every marketing problem by adding a new tool is how stacks become unmanageable. Sometimes the right answer is fewer tools, better implemented.
Neglecting permissions and governance architecture from the start. Who can publish what, from where, with what level of approval required, is not an afterthought. A local operator accidentally publishing a promotional price that differs from another location’s active offer creates a real customer problem. A local social account posting something off-brand because permissions were set too loosely creates a brand problem. These scenarios happen more often than they should because governance was designed for the early business and never updated as the footprint grew.
What Mature Organisations Actually Build
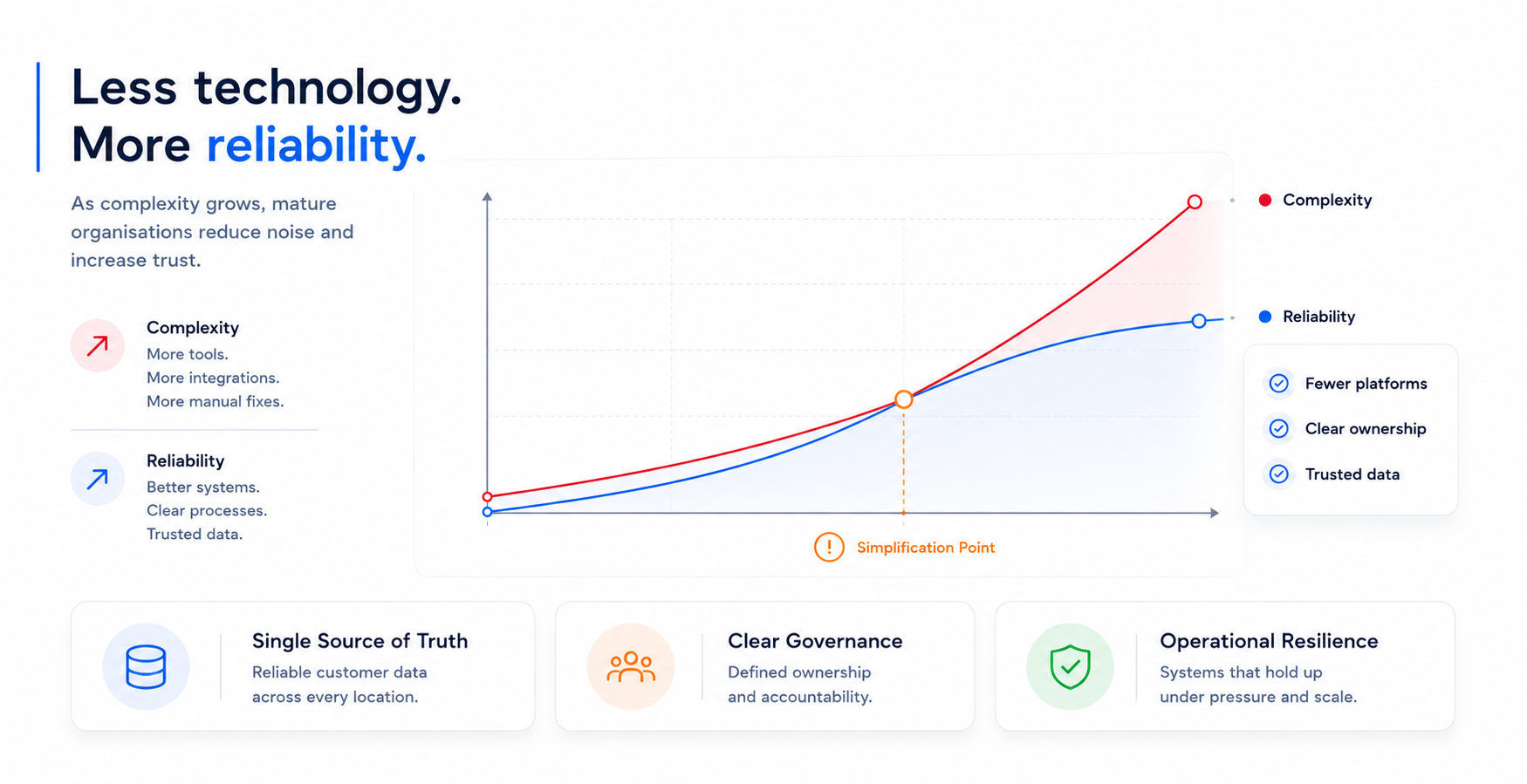
By the time a multi-location business has genuinely figured out its marketing infrastructure, the system it has built usually looks less impressive than what it started with. Fewer platforms. Cleaner integrations rather than elaborate automation chains. Reporting frameworks that surface fewer metrics but track them reliably, rather than dashboards full of data nobody fully trusts.
This is not an accident. The complexity that accumulates during rapid growth eventually forces a reckoning. The organisations that come out of that reckoning well are the ones that resist solving operational problems by adding more technology and instead ask harder questions about process, ownership, and what the system actually needs to do.
They tend to have made a few specific choices that distinguish them. They have a single source of truth for customer data, which is not the same as having every location on the same CRM. It means clear data governance: which system owns which data and how it flows between systems. They have built reporting architecture around questions the business actually needs to answer, rather than around what the analytics platform makes easy to measure. And they have invested in making local operators genuinely capable users of the system, not just technically onboarded into it.
What Resilience Actually Looks Like
The most resilient marketing stacks are usually the quietest ones. They do not generate a lot of internal conversation because they are not constantly breaking. Local operators know how to use them. Central teams can get the information they need without running manual reports. When something does go wrong, the problem is contained and diagnosable rather than systemic and mysterious.
This kind of resilience is not glamorous. It does not make for a compelling slide in a board presentation. It is the result of accumulated unglamorous decisions: choosing a simpler integration over a more powerful but fragile one, rebuilding a data structure that was causing downstream problems even though no single person was asking for it, maintaining documentation that nobody celebrates but everyone depends on.
The companies that build well at 100 locations are usually the ones that stopped treating their marketing stack as a proof of sophistication and started treating it as infrastructure. Infrastructure is not supposed to be interesting. It is supposed to work, reliably, at volume, when the people depending on it are not thinking about it at all. That is a harder thing to build than it sounds, and a more valuable one than most organisations realise until they no longer have it.
The signal is usually a cluster of symptoms rather than a single breaking point. When manual workarounds have become load-bearing parts of the workflow, when data inconsistencies across locations are producing reporting you can no longer trust, and when onboarding a new location requires significant central team involvement every time, the stack is no longer scaling. The instinct at that stage is usually to add another integration or hire someone to manage the gap. That instinct is almost always wrong. Patching a structurally misaligned system extends the problem and increases the eventual cost of fixing it. The right moment to rebuild is when the workarounds have become the system, not after they have caused a visible failure.
Good data governance in a multi-location context starts with a clear answer to one question: which system is the source of truth for each type of data, and how does data flow from there to everywhere else? This means defining which platform owns customer records and how location-level data feeds into it, rather than allowing each location to maintain its own disconnected database. It means standardising the fields, naming conventions, and data entry protocols that every location uses, and building the quality monitoring that flags when a location has drifted from the standard. Governance does not require every location to use identical tools. It requires that the data produced by every location is structured consistently enough to be aggregated and compared meaningfully at the centre.
The most useful principle is to centralise the things that affect the integrity of the system if done inconsistently, and leave local choice over the things that genuinely benefit from local judgment. Data structures, reporting frameworks, brand asset libraries, core campaign architecture, and permission settings all need central ownership because inconsistency in any of these degrades the whole system. Channel selection within an approved set, local content themes, community-specific promotions, and timing adjustments for local conditions are all areas where local operators have better information than a central team and where variation is unlikely to create downstream problems. The mistake most organisations make is centralising decisions in the second category because it feels like control, while leaving decisions in the first category inconsistently managed because nobody claimed ownership.
Several things happen in parallel. The integration dependencies that were invisible at launch start failing as one or both platforms update their underlying systems. The governance that was maintained carefully during the implementation phase relaxes as the team moves on to other priorities, and data quality drifts. Local operators who were trained at onboarding develop workarounds for the parts of the system that don't fit their workflow, and those workarounds become habits that get passed on to new staff without anyone noticing. And the business itself changes in ways the original stack design didn't anticipate, adding new locations with different configurations, new channels that weren't part of the original architecture, new reporting requirements that don't map cleanly onto what the system was built to measure. The stacks that hold up well are the ones that were designed with an explicit maintenance model, not just an implementation plan.
Buying ahead of operational readiness. It is very common for growing multi-location businesses to purchase marketing platforms based on what the business will need at scale, before the processes, data standards, and internal capability exist to use those platforms effectively. A sophisticated personalisation engine is not useful if the customer data feeding it is inconsistent and unverified. An advanced attribution model is not useful if campaigns across locations are not tagged consistently enough to track. An automated campaign distribution system is not useful if brand standards are not clear enough to set the guardrails the automation depends on. The result is expensive software that gets used at a fraction of its capability, erodes confidence in the category of tool, and often gets replaced with something simpler that the organisation can actually operate. The correct sequence is operational readiness first, then the technology investment that the readiness can support.