Research Labs
The Geo-Targeting Precision Trap: How Granular Should Your Location Targeting Actually Get?
When hyper-precise location targeting starts costing more than it earns — and how multi-location brands can find the right depth before scale collapses.

There is a point in every multi-location media plan where the targeting gets too precise for its own good. You start at city level. Then someone suggests breaking it down by ZIP code. Then radius targeting around each location. Then layering demographic signals. Then day-parting by location. Before long, you have 40 campaign segments for a brand with 12 locations, and half of them are spending $11 a day against audiences too thin to generate statistically meaningful signal.
We have seen this play out across retail chains, fitness franchises, urgent care networks, and regional restaurant groups. The instinct to get hyper-specific feels like rigor. Often, it is the opposite. Precision without adequate volume is noise, not signal. And the operational overhead of maintaining over-segmented geo structures quietly destroys campaign quality over time.
This article is about how to think about targeting depth strategically — when to go narrow, when to stay broad, and how to build structures that actually scale.
City-Level vs. ZIP-Level vs. Radius vs. Hyperlocal: What Each Layer Actually Does
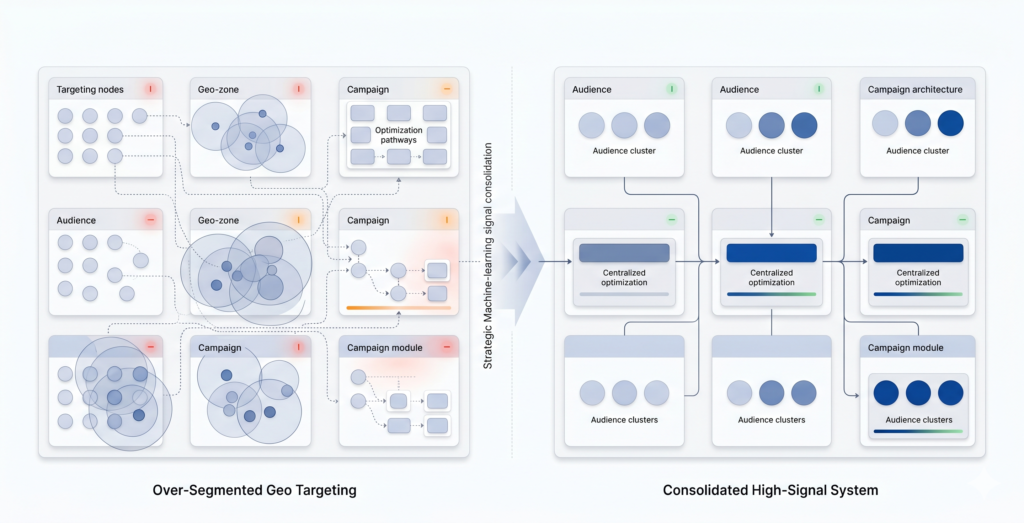
These four targeting approaches are not just points on a spectrum. They interact differently with ad platform algorithms, audience size requirements, attribution logic, and creative strategy. Treating them as interchangeable is one of the most consistent mistakes we see in multi-location campaign builds.
City-Level Targeting
City-level targeting tells the platform to reach people within a defined municipal boundary. It is broad enough to maintain meaningful audience pools and gives machine learning algorithms sufficient data to optimize effectively. For brands with a strong local brand presence or multiple locations within the same metro, city-level targeting often outperforms more granular approaches on a cost-per-acquisition basis — not because it is lazy, but because the algorithm has enough room to find high-intent users efficiently.
ZIP Code Targeting
ZIP code targeting is where most multi-location teams first feel like they are being “precise.” In practice, the performance delta between ZIP-level and city-level depends heavily on whether there is a genuine strategic reason to differentiate — a competitor cluster in one ZIP, a demographic skew, a different commuter pattern. Without a documented rationale, ZIP segmentation mostly adds management complexity without improving outcomes.
There is also a data density problem. When you split a city of 600,000 people into 18 ZIP codes and apply additional demographic filters, several of those ZIPs will have audiences under 5,000 people. Meta and Google’s auction systems are built for volume. Thin audiences mean higher CPMs, reduced delivery, and slower learning cycles.
Radius Targeting
Radius targeting is appropriate for drive-to locations with a defined service area: a single-location medical clinic, a QSR with clear trade area data, a gym in a mixed-use development where the surrounding residential density is well understood. The logic is defensible when the radius is built on real behavioral data rather than gut instinct.
The common mistake is using the same radius template across every location regardless of urban density, competitive proximity, or trade area overlap. A 5-mile radius in downtown Chicago captures a different behavioral and demographic mix than a 5-mile radius in suburban Columbus. Applying them the same way produces different results and then nobody understands why.
Hyperlocal Targeting
Hyperlocal targeting — typically defined as targeting at the block, neighborhood, or building level — has legitimate use cases: event-based geofencing, conquesting competitor locations, targeting specific commercial developments, or reaching a highly defined micro-demographic cluster. It is powerful in isolation. It becomes expensive when applied at scale across a national brand footprint.
At this level of granularity, audience size frequently falls below platform minimums for effective optimization. Signal fragmentation accelerates. And creative relevance requirements increase substantially — an ad that speaks to someone within 500 meters of a location needs to be meaningfully different from one delivered to someone two miles away, or the precision is wasted.
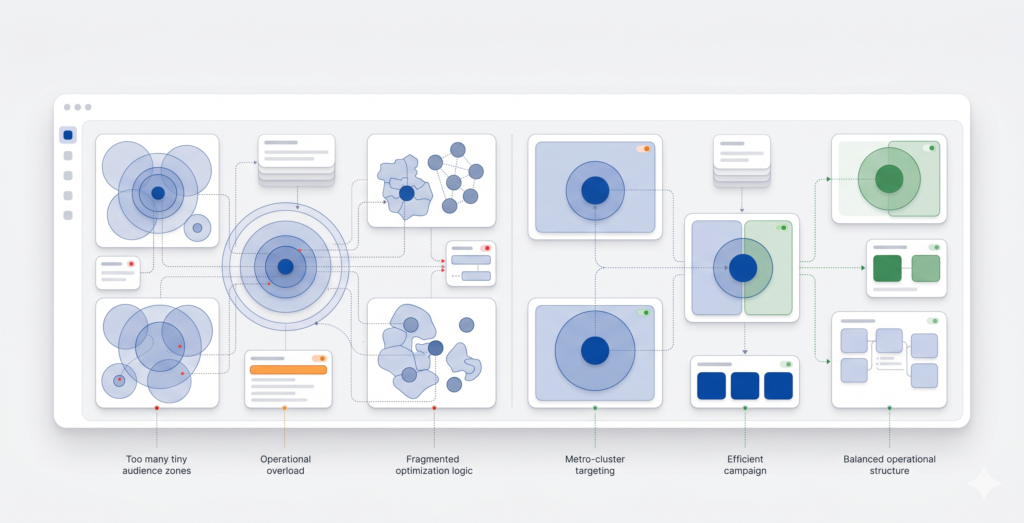
When Hyperlocal Targeting Improves ROI — and When It Damages Scale
The ROI case for hyperlocal targeting is real but narrow. It works reliably in these scenarios:
- High transaction value, low traffic volume: A luxury car dealership geofencing luxury apartment buildings can justify the cost-per-reach because a single conversion covers thousands of impressions.
- Competitive conquesting: Geofencing a direct competitor’s location to intercept customers at the moment of decision is one of the cleaner use cases for tight radius targeting.
- Event-driven campaigns: Reaching people physically present at a trade show, stadium, or conference — where behavioral context is extremely defined — justifies hyperlocal precision.
- Last-mile service businesses: HVAC, plumbing, moving services, and other service-area businesses often see strong performance from tight radius targeting around service zones, particularly when paired with day-parting.
Where it reliably fails: when it is applied systematically across 50+ locations without per-location budget thresholds, when the audience density cannot support the algorithmic learning requirements of modern ad platforms, or when the creative is not differentiated enough to justify the segmentation.
A regional fitness chain we work with had built individual hyperlocal campaigns for each of its 28 locations. Average daily spend per location: $18. At that budget level, most campaigns were stuck in the learning phase permanently. Consolidating to metro clusters and raising individual budgets by consolidating spend improved conversion volume by 34% within six weeks — without changing a single ad creative.
The Hidden Operational Costs of Over-Segmentation
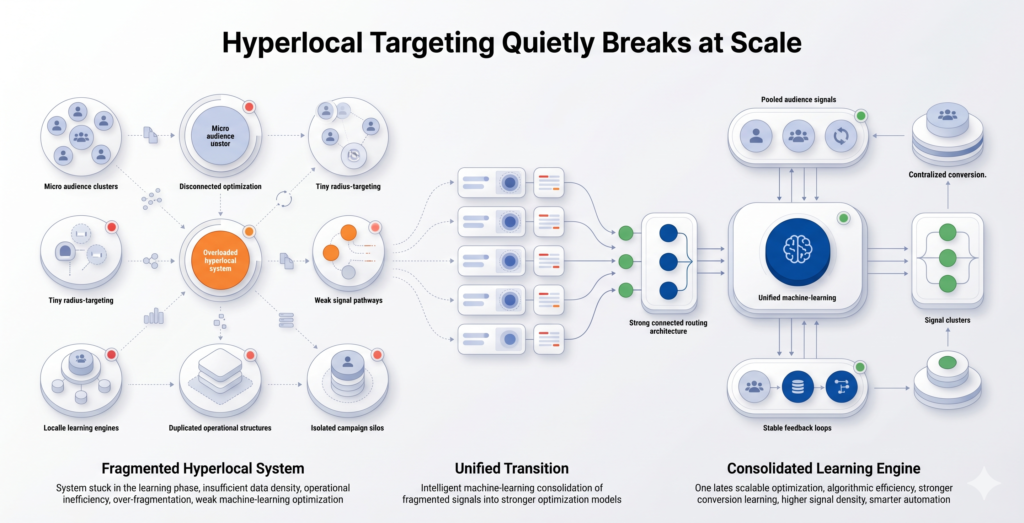
Geo-targeting discussions focus almost entirely on audience quality and bid efficiency. They underweight the operational cost of maintaining highly segmented geo structures over time.
Consider a franchise brand with 60 locations, each running individualized ZIP-level campaigns. That structure requires managing 60+ campaign sets, with individual budget pacing, bid adjustments, negative keyword management, creative updates, and performance reviews. In practice, most paid media teams do not have the bandwidth to review 60 campaigns meaningfully each week. What happens is that underperforming campaigns receive delayed attention, budget pacing drifts, seasonal adjustments happen inconsistently, and the structure becomes semi-autonomous in ways nobody intended.
There is also the creative management problem. Genuinely localized ads — not just location name insertion, but content that reflects a local offer, a neighborhood-specific value proposition, or a location-relevant message — require production resources. If the creative is not actually differentiated, the segmentation is not adding value. If it is differentiated, someone has to build and maintain those assets at scale.
Brands usually underestimate this burden in the planning phase and feel it acutely at the six-month mark.
Signal Loss, Data Fragmentation, and the Privacy Layer
The mechanics of modern ad platform optimization are not neutral observers of targeting decisions. They are active participants. Meta’s Advantage+ and Google’s Performance Max are both designed to maximize signal aggregation — they perform better with larger audiences and more conversion data, not less.
When you over-segment geographically, you are working against the grain of how these platforms allocate optimization resources. A campaign with 200 conversions teaches the algorithm significantly more than 10 campaigns with 20 conversions each, even if the geographic clusters are broadly similar.
Privacy changes have made this worse. Apple’s ATT framework, the deprecation of third-party cookies, and the general degradation of location precision in mobile signals mean that the location data informing geo-targeted campaigns is already less precise than it was three years ago. Targeting granularly on top of imprecise location data compounds the accuracy problem. A “1-mile radius” campaign in a post-ATT environment may be reaching people within 1.5 to 3 miles of that pin point, depending on the device, the platform, and the consent state.
First-party data remains the most reliable input for location-based advertising strategy. Brands that have mapped their customer trade areas using CRM data, loyalty program addresses, or in-store transaction data have a structural advantage. They can build lookalike audiences anchored in real behavioral geography rather than inferred proximity.
How Google Ads, Meta, and Programmatic Platforms Interpret Geo Signals Differently
This is a practical point that gets glossed over in most geo-targeting discussions: platforms do not handle location data the same way.
Google Ads uses a combination of location of interest (where a user is searching about) and physical presence. This means a user in Phoenix can be targeted in a Los Angeles campaign if their search behavior suggests LA intent. For multi-location brands, this is generally an asset — it captures out-of-area intent. But it means pure radius campaigns on Google are not as geographically rigid as they appear in the settings panel.
Meta Ads relies primarily on device location data, user-reported location, and behavioral signals. The “people living in or recently in this location” option behaves differently from “people traveling in this location.” Most multi-location brands use the default without scrutinizing which signal set is actually driving delivery.
Programmatic platforms (DSPs using bid-stream location data) are working with the least precise and most variable geo signal of any major channel. Location data quality varies significantly by data provider, and the same campaign brief delivered through two different DSPs with different data partners can produce meaningfully different geographic distributions.
The implication for geo-targeting strategy is that location settings in campaign interfaces are starting points, not precise technical controls. Building a campaign architecture that assumes platform location signals are binary and exact will produce results that do not match expectations.
Practical Frameworks for Deciding Targeting Depth
The right targeting depth is a function of four variables: budget per location, audience density, competitive landscape, and creative differentiation capability. A rough framework our teams use:
Tier 1: City-Level or Metro Clustering Appropriate when: monthly budget per location is under $3,000; locations are within the same metro; audience density is high; no meaningful geographic variation in customer profiles.
Tier 2: ZIP or Neighborhood Segmentation Appropriate when: monthly budget per location exceeds $5,000; trade area data supports ZIP-level differentiation; competitive clustering justifies targeted messaging; creative infrastructure can support segment-specific assets.
Tier 3: Radius or Hyperlocal Appropriate when: monthly budget is $8,000+; trade area data is precise (first-party or third-party verified); use case is conquesting, event-based, or high-value transaction; creative is genuinely differentiated at this level.
Budget thresholds are not arbitrary. They reflect the minimum spend required to generate the conversion volume needed for algorithmic optimization to function. Below threshold, narrower targeting produces higher CPCs, incomplete learning cycles, and unreliable performance data.
Urban vs. Suburban Markets: Why the Same Strategy Fails Differently
A 2-mile radius in Manhattan can encompass 500,000 people. The same radius in suburban Nashville might cover 30,000. The same targeting parameters in both markets produce results that are structurally incomparable — and yet we routinely see franchise systems apply identical geo-targeting templates nationally.
In dense urban markets, the challenge is the opposite of what most assume: not audience scarcity, but creative relevance. High-density urban audiences are not necessarily high-affinity audiences for a given location. The physical proximity of many people does not mean they are the right people or that they would realistically patronize that location over a competitor one block away.
In suburban and exurban markets, the problem is population density and drive-time trade areas that extend further than ad platforms can efficiently target. A consumer in a suburb may drive 15 minutes to a location but live outside the default radius setting. Service-area businesses in these markets often perform better with expanded radii and intent-based layering than with tight hyperlocal approaches.
Why Franchise Systems Overcomplicate Their Targeting Structures
Franchise advertising is structurally challenging for geo-targeting because it sits at the intersection of national brand standards and local operator preferences. The typical result is a hybrid structure that satisfies neither.
Franchisees want to feel like their media budget is working for their specific location. That pressure drives toward hyper-granular targeting. Corporate marketing wants brand consistency and performance accountability. That pressure drives toward standardization. The compromise is often a middle-ground architecture with more segmentation than the budget can support and less brand control than the system requires.
What we observe consistently is that franchise systems benefit more from rigorous trade area mapping and budget allocation discipline than from targeting granularity. Knowing that Location A serves a 4-mile trade area while Location B serves a 7-mile trade area — and budgeting accordingly — produces better results than splitting both into identical 2-mile radius campaigns and hoping for the best.
The Direct Answer: How Granular Should Your Geo-Targeting Actually Get?
Go as granular as your budget, data quality, and creative infrastructure can genuinely support — and no further.
For most multi-location brands, this means city-level or metro clustering with demographic and behavioral layering is the right default. ZIP or radius segmentation should be reserved for locations where trade area data, competitive dynamics, or budget thresholds justify the added complexity. Hyperlocal targeting belongs in a specific toolkit: conquesting, event-based campaigns, high-value transactions, or locations with documented micro-demographic variation.
The test is operational as much as strategic: if you cannot review every geo segment meaningfully every week, your structure is too complex for your resources. If your per-segment budgets are too low to exit the learning phase on Google or Meta, your structure is too granular for your spend level. Consolidate until both constraints are satisfied, then add depth only where data supports it.
Conclusion
Geo-targeting precision is not a virtue in itself. It is a tool with a specific operating range — effective within certain budget, data, and creative parameters, and actively counterproductive outside them. The brands that perform consistently in location-based advertising are not the ones with the most granular targeting structures. They are the ones that understand where precision adds value and where it just adds complexity.
For multi-location brands serious about local customer acquisition, the more important investments are in trade area intelligence, first-party data infrastructure, and budget allocation discipline. Those foundations make any level of geo-targeting more effective. Without them, granularity is just noise dressed up as strategy.